

서버이중화
MSCS
클러스터는 두 개 이상의 서버를 함께 연결하므로 클라이언트에는 하나의 컴퓨터로 나타납니다.
이들은 서로
연결되어 있으며, 하나가 실패하면 MSCS가 장애 복구를 수행하여 실패한 서버로부터 클러스터에 있는 다른 컴퓨터로
어플리케이션의 상태
데이터를 전송하고 그 서버에서 해당 조작을 다시 시작하는 방식으로 구성됩니다.
클러스터 내에서 서버를 연결하면 작업 부하를 분산시키고 작업
및 관리를 단일 위치에서 제어할 수 있을 뿐 아니라 갈수록 늘어나는 확장성에
대한 요구 사항도 충족시킬 수 있습니다. 즉, 클러스터링을
사용하면 고가용성 응용 프로그램을 만들 수 있습니다.
세 가지 클러스터링 기술
Microsoft 서버는 클러스터링을 지원하는 세 가지 기술 즉, NLB(네트워크 로드 균형 조정), CLB(구성
요소 로드 균형 조정) 및
MSCS(Microsoft Cluster Service)를 제공합니다.
- 네트워크 로드 균형 조정
- 네트워크 로드 균형 조정은 들어오는 IP 트래픽을 서버 클러스터에 분산시키는 프런트 엔드 클러스터의 역할을 하며 전자 상거래 웹 사이트에
필요한
점진적인 확장성과 뛰어난 가용성을 제공하는 이상적인 기술입니다. 최대 32개의 Windows .NET Enterprise Server를 연결하여 하나의 가상 IP 주소를
공유할 수 있습니다. NLB는 클러스터 내의 여러 서버에 걸쳐 클라이언트 요청을 분산시킴으로써 확장성을 향상시킵니다. 트래픽이 증가함에 따라
클러스터에 서버를 추가할 수 있습니다. 하나의 클러스터는 최대 32개의 서버로 구성할 수 있습니다. 또한 NLB는 사용자에게 지속적인 서비스를 제공하는
동시에 서버의 오류를 자동으로 감지하고 남아 있는 서버에 클라이언트 트래픽을 10초 이내에 재분배함으로써 고가용성을 제공합니다. - 구성 요소 로드 균형 조정
- 구성 요소 로드 균형 조정은 사이트의 비즈니스 로직을 실행하는 여러 서버에 걸쳐 작업 부하를 분산시킵니다. 최대 8개의 동일한 서버
집합에 걸쳐 COM+
구성 요소의 동적 균형 조정 기능을 제공합니다. CLB에서 COM+ 구성 요소는 각기 다른 COM+ 클러스터의 서버에 있습니다. COM+ 구성 요소를 활성화하는
호출이 발생할 경우 COM+ 클러스터 내의 여러 서버들 간에 로드 균형 조정이 이루어집니다. CLB는 다중 계층 클러스터 네트워크에서 중간 계층 역할을
수행함으로써 NLB와 클러스터 서비스를 보완해 줍니다. Application Center 2000의 기능으로 CLB가 제공됩니다. CLB 및 Microsoft Cluster Service는 동일한
컴퓨터 그룹에서 실행할 수 있습니다. - 클러스터 서비스
- 클러스터 서비스는 백 엔드 클러스터 역할을 하며 데이터베이스, 메시징과 파일 및 인쇄 서비스와 같은 응용 프로그램에 대해 고가용성을
제공합니다.
MSCS는 노드(클러스터의 서버)에 오류가 발생하거나 노드가 오프라인 될 경우로 인한 시스템의 오류를 최소화해 줍니다.

결론
Microsoft Cluster Service는 컴퓨팅 리소스를 최소화하는 동시에 저렴한 표준 하드웨어를 사용하여
고가용성을 제공합니다. Windows Server
2003의 클러스터 서비스는 응용 프로그램의 가용성을 높이기 위한 강력한 도구를
제공합니다. 클러스터를 인식하는 응용 프로그램을 바로
작성하려고 시도하는 것은 일부 개발자들에게 있어 비용이 너무 많이 들거나 어렵게
느껴질 수 있습니다. 개발자들이 매우 저렴한 초기 투자
비용으로 클러스터링의 이점을 확인해 볼 수 있도록 클러스터 서비스는 일반 응용
프로그램 리소스 형식을 제공합니다. 이 리소스 형식을
사용하면 클러스터 내에서 응용 프로그램을 실행하도록 쉽게 구성할 수 있습니다. 일반
응용 프로그램 리소스 형식은 작업용 응용 프로그램에서
필요로 하는 복잡한 기능을 제공하지는 않지만 클러스터 내에서 응용 프로그램의 수행
방식을 확인할 수 있는 리트머스 테스트를 제공합니다.
MCCS
오늘날 미션 / 비즈니스 크리티컬한 환경에서 애플리케이션 서비스는 중단 없이 운영되어야 합니다.
즉, 장애로 인한 서비스 다운 타임은 비즈니스 손실로 연결되며, 더 이상 허용되어서는 안됩니다. 맨텍의 MCCS는 서버, 애플리케이션 서비스,
네트워크, 스토리지 뿐만 아니라 시스템 리소스와 애플리케이션 리소스 문제로 인한 장애에 대해서 서비스 연속성을 보장하고 가용성을 극대화
할 수 있는 솔루션 입니다. MCCS는 자동 장애처리 및 실시간 데이터 복제를 통해서 미션 / 비즈니스 크리티컬한 애플리케이션을 24 x 7 /
365일
운영 할 수 있도록 합니다. 또한 중요한 이벤트 발생시 SMS 알람을 통해 장애에 대한 전파 및 후속조치를 신속히 수행할 수 있습니다.
-

서버 클러스터링
MCCS는 서버 하드웨어, 소프트웨어, 네트워크, 스토리지 등 장애 유형에 관계없이 모든 애플리케이션을 24 x 7 x 365일
운영 할 수 있습니다. MCCS는 모든 애플리케이션의 유형에 대해서 보호가 가능하며, 서버 클러스터링을 통해 다운타임을
수분에서 수초로 최소화 합니다. -

실시간 블록 복제
블록 레벨 복제로 타깃과 소스의 데이터 정합성 보장 합니다. 두 서버 사이에 데이터 복제 모듈이 구성 되면, 소스볼륨에
쓰기 작업이 발생 시 TCP/IP 네트워크를 통해서 타깃 볼륨에 동시에 쓰기 작업을 수행하게 됩니다. MCCS는 모든 종류의
파일과 데이터베이스를 지원하며, 장애 및 재해에 대해서 중요한 데이터가 손실되지 않습니다. -

통합 가용성 관리
맨텍의 클라우드 기반의 글로벌 관리 센터를 통해 여러 분산된 클러스터를 한 눈으로 관리할 수 있습니다.
또한 가용성 보고서를 통해 가용성 관련한 통계정보를 직관적으로 볼 수 있습니다.
신뢰성
- 클러스터링 기능
- 오라클 RAC은 서버 장애 시 빠른 failover를 제공하는 고 가용성 솔루션입니다.
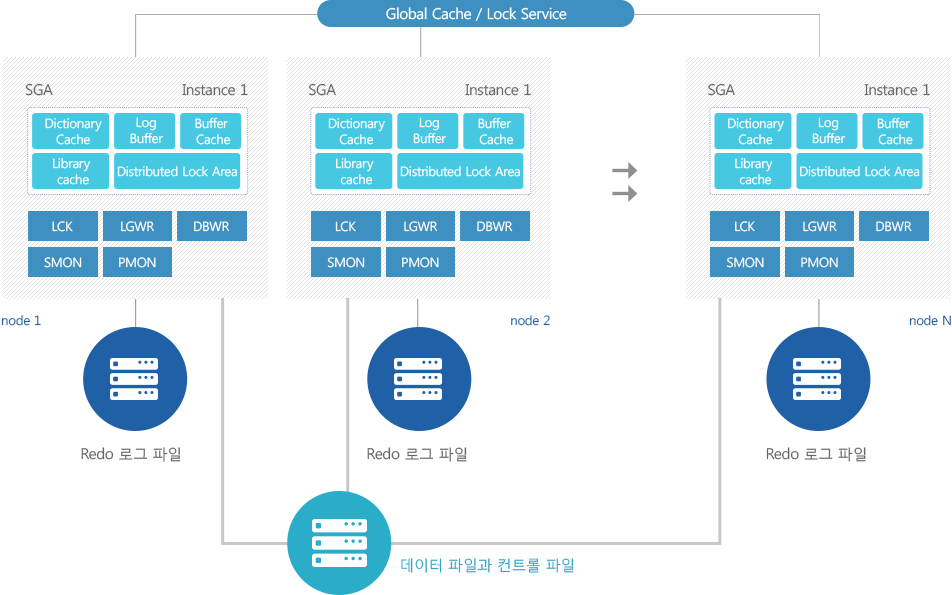
- ㆍRAC 클러스터링은 major OS/플랫폼 전부에 대해 지원됩니다.
- ㆍLocking이 global하게 관리되기 때문에 트랜잭션의 정합성은 완벽히 보장됩니다.
- 클러스터링 기능
- RAC은 디스크를 공유하는 Active/Active 구성으로서 특정 노드에 장애가 발생해도 어플리케이션은 영향을 받지 않고 지속적인
연결을 유지합니다.
클러스터 상의 다른 노드가 살아 있다면, 모든 사용자가 이 노드 들을 통해 프로세싱을 계속할 수 있습니다.
TAF (Transparent Application Failover) 기능을 활용하면 세션의 failover가 가능합니다. Failover된 트랜잭션은 정합성을 위해 재시작 되어야 합니다.
TAF 기능 활용하면 세션의 Failover 가능
Failover된 트랜잭션은 정합성을 위해 재시작
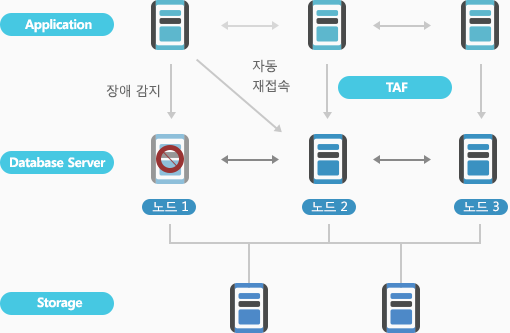
- 특정 한 노드가 장애가 발생해도 전체 서비스는 다른 노드를 통해 지속됨
- - 클러스터 방식이 아닌 SMP
- - 서버에서는 전체 다운으로 불가능
- 오라클 RAC는 디스크를 공유하는 Active-Active 구조임
- TAF는 OCI 드라이버 런타임 기능
- - OCI, JDBC Thick 드라이버에서 제공
- 장애 발생 시 응용 프로그램이 자동 재 접속함
- - 이 과정에서 트랜잭션을 롤백
- - Basic과 Preconnect 방식
- 클러스터링 기능
- 공유 디스크 & 공유 캐시 기반의 클러스터 시스템은 아키텍처 자체에 시스템 장애에 대해 강력한 오류 내구성(Fault Tolerance)을 내장하고 있습니다.

- 장애 복구 절차
- 1. 3번 노드 장애
- 2. 클러스터 membership 재구성
- 3. 3번 노드의 작업 복구
- 4. 서비스 재개
공유 디스크 & 공유 캐시 구조의 아키텍처에서만 가능한 “Hot failover”
- - 클러스터 내에 살아 있는 서버 노드가 있는 한 서비스는 중단되지 않습니다.
- - 공유 디스크 구조이므로 failover 과정에서 데이터에 대한 아무런 조작이 필요 없습니다.
- - 모든 서버 노드들이 active 상태로 동작하는 구조이므로 매우 빠른 failover가 가능합니다.
클라이언트를 위한 failover 기능 제공
- - 장애 상태인 서버에 접속 시 자동으로 살아있는 다른 노드로 재접속
- - 접속 상태에서 장애 발생 시, 서비스 요청 실패와 함께 자동으로 살아있는 다른 노드로 재접속
- - 접속 상태에서 장애 발생 시, 장애 발생 이벤트를 받아 자동으로 살아있는 다른 노드로 재접속
유지보수성
- 온라인 운영관리 기능
- RAC 상에서 노드 추가 및 삭제가 온라인 중에 가능합니다.
클러스터(RAC) 상에서 온라인 노드 교체 과정
-
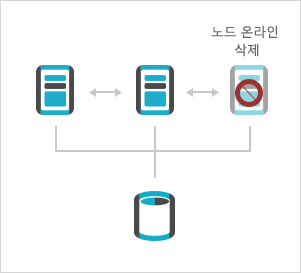
- 1RAC 노드 삭제
- - CRS 서비스 제거
- - RAC 환경 설정 제거
- - OS 환경 설정 제거
-
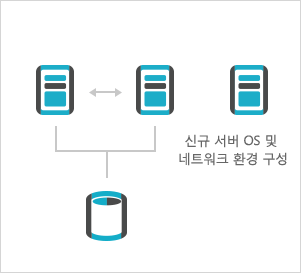
- 2벤더 클러스터 및 공유 디스크 절체
- - 삭제 인스턴스 용 Redo, Undo
- 3신규 노드 클러스터 및 공유 디스크 구성
- - OS 및 네트워크 환경 구성
- - 클러스터 노드 추가
- - 공유 디스크 환경 구성
-

- 4RAC 환경 구성 및 노드 추가
- - Oracle Cluster 노드 추가
- - RAC 환경 파일 구성(신규)
- - 신규 노드 시작
- - 서비스 등록
- 온라인 운영관리 기능
- RAC 상에서 DBMS 중단 없이 Rolling Patch 업그레이드가 가능합니다.
Rolling Patch Upgrade Using RAC
하나 이상의 인스턴스가 존재하는 RAC는 DBMS의 중단없는 유지 보수 작업 기능도 제공할 수 있습니다.
-
1

Initial RAC Configuration
-
2
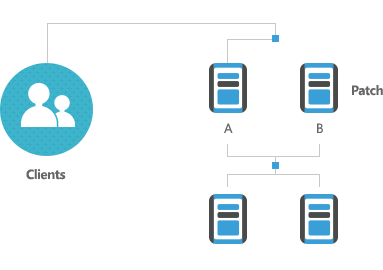
Clients on A, Patch B
-
3
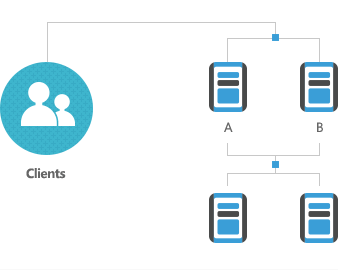
Upgrade Complete
-
4
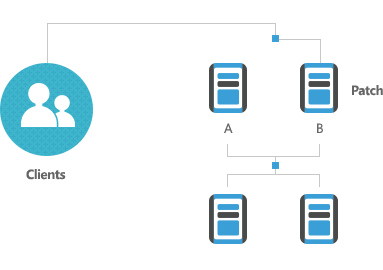
Clients on B, Patch A
- Oracle Patch Upgrades
- Operating System Upgrades
- Hardware Upgrades
4세대 HA(High Availability)
RoseHA는 1993년 3월 실리콘밸리 R&D에서 출발하여 전 세계(미국, 영국, 독일, 일본,
대만, 중국, 홍콩…) 12만 고객이 안정적으로 사용하고 있는
4세대 HA솔루션으로 국내에서도 전 산업영역에 고객사례를 보유하고 있습니다.
-
- 01. 사전시스템 Hang 대처
- 시스템 리소스(CPU, Memory, Disk, Network…)의
상태를 체크하여 “시스템 Hang”과 같은 상황 이전
유연한 서비스 Failover 제공
-
- 02. 데이터 시점복구
- 잘못된 마이그레이션, 바이러스 공격 등으로 손상된
데이터를 “Point-in-time Rollback”기능으로 복구 가능
원격지 데이터 복제 시 “압축 및 시점복구” 지원
-
- 03. 통합 모니터링 및 관제
- Server, Network, Application, Performance, Data 보호는
물론, 중앙에서 통합 모니터링 및 관제를 통한 “Continuous
Availability 환경”을 제공
구성방식 지원
RoseHA (Multi-node)
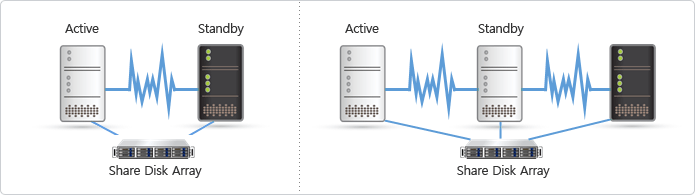

특.장점
1완벽한 장애대처
- Wizard 방식의 가장 간편한 설치 및 구성
- 데이터베이스, 응용프로그램, 네트워크, 디스크, 전원 등의 장애 상황에서의 유연한 페일오버를 지원하여 서비스 연속성을 보장
- I/O Fencing, 사전 Hang 대처, 시점복구, Deep Check 등의 4세대 기술을 통한 안정적인 HA 운영 보장
- 통합 모티터링 및 관제 GUI 제공하여 손쉽게 여러 HA 세트를 중앙에서 관리
통합 관제 및 모니터링
안정적인
HA 운영
-
I/O Fencing
GUI를 통한 Arbitral Disk 제어 ·
데이터 깨짐 방지 기능 제공 ·
실 데이터 볼륨에 대한 Fencing ·
-
시점복구
· GUI를 통한 시점백업 및 복구 구성
· 시점백업 주기 설정
· 원본데이터 손상에 따른 신속한 Data 복구
-
사전 Hang 대처
사전 Hang 대처 ·
시스템 장애의 정밀한 대처를 위한 모니터링 ·
Hang을 유발하는 요소 별 임계치 설정 ·
-
Deep Check
· DB 또는 APP Hang 대처를 위한 Deep 모니터링 제공
· GUI를 통한 손쉬운 설정 (no script)
2실시간 복제와 시점복구
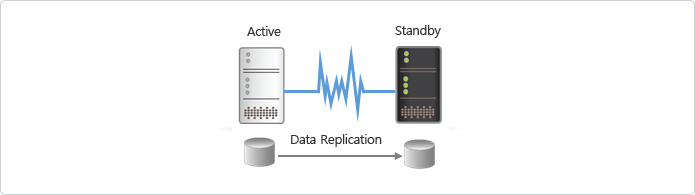
- Active 서버와 Standby 서버간의 실시간 Data 복제를 통한 정합성 유지
- 원하는 Files, Folders, Volumes등 선택적 복제 지원(드라이브 위치 및 속성 무관)
- Failover 이후 자동 데이터 역 Sync 지원
- 바이러스 공격이나 사용자 실수에 의한 원본 Data 손상 발생시 시점복구(Data Rewind)를 지원하여, 장애 이전 시점의 Data 복구 수행
- 복구 상태 모니터링 및 정확한 진단



3Linux, Windows 가상화 지원
- 다양한 가상화 하이퍼바이저 지원
- 공유스토리지 환경의 이중화 지원
- 실시간 데이터 복제 환경 이중화 지원
- 개별 가상머신(VM)의 응용프로그램 장애 감지 및 페일오버 지원
- Rose HA를 통한 운영 VM 이미지 이중화
- 가상화 환경에서의 I/O Fencing, 성능모니터, 시점복구, Deep Check 등의 4세대 기술을 통한 안정적인 가상화 HA 운영 보장
- VMware vCenter에 통합 (Plug-in)

4통합 관제 서비스
- 단일 GUI를 통해 여러 HA 노드를 중앙집중 관제 및 모니터링
- 전체 이중화 시스템의 장애여부 한눈에 파악
- E-mail, SNMP, SMS 등 다양한 방법으로 사용자 알람
5Virtual MAC 지원
- RoseHA는 가상 MAC을 지원하여 Active-Standby 환경에서 동일한 MAC 주소를 제공 함으로써 MAC 기반 통신 및
인증 등의 환경에서 유연한
이중화 구성이 가능 - Alias(NetBIOS)의 완벽한 지원으로 Client의 수정 없이 간편하게 HA 구성이 가능
- Client의 환경 설정 변경 및 Shutdown, Restart 등의 불필요한 작업을 제거

